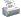¿Qué os parece esta gráfica para Ollama local con modelo básicos?
Click aquí
13-jun-2026 19:28
#1
|
Hola: Tengo un servidor básico para cosillas mías con modelos en local. Es este: https://www.info-computer.com/dell-p...win-11-dp.html Voy a meterle GPU para darle vidilla a mi Ollama en local, que se me está quejando mucho. Nada profesional, aunque tampoco quiero que vaya a 5 tokens por segundo. Leyendo mucho y tirando de IA, he llegado a esta: Amazon El resumen es este: 3. MSI GeForce RTX 5060 Ti 16G INSPIRE 2X OC (589 €) - La Elección Óptima Esta opción es perfecta para tu situación por múltiples factores: Velocidad de Memoria Revolucionaria: Al ser de la serie 5000, incluye 16 GB de la nueva tecnología de memoria GDDR7. Esto eleva el ancho de banda a 448 GB/s (frente a los 288 GB/s de la generación anterior). Para la inteligencia artificial local, esto se traduce directamente en que el modelo escribirá texto o código a una velocidad muchísimo mayor. Compatibilidad Física Garantizada: Este modelo es muy compacto, midiendo apenas 204 mm de longitud. Entrará de manera holgada en tu torre Dell sin requerir que modifiques ni retires ninguna pieza de plástico del interior. Eficiencia Energética: Su consumo máximo ronda los 180W, lo que la mantiene en un rango manejable para la actualización de energía que discutimos. Precio: Sorprendentemente, a 589 €, es la más barata de las tres, ofreciéndote tecnología superior a un costo menor. Respecto a tu duda sobre el futuro: esta nueva tarjeta utiliza el estándar de conexión PCI Express 5.0. En tu actual Dell funcionará perfectamente acoplándose a tu ranura PCIe 3.0, pero te garantiza una longevidad excepcional. El día de mañana, cuando la instales en un ordenador de nueva generación, aprovechará todo el ancho de banda del estándar 5.0, haciéndola una inversión extremadamente sólida a largo plazo. Opiniones forococheras? Gracias |
ForoCoches: Miembro
13-jun-2026 19:38
#3
|
589€... Madre mia. Yo tengo una de zotac y me costó 435 o algo asi. He visto 5070 a precios muy parejos, pero claro, tiene solo 12gb aunque mayor ancho de banda. Tiene bastante mayor potencia esta última. ¿Te podría servir a pesar de tener menos gb? |
ForoCoches: Miembro
13-jun-2026 20:37
#4
|
hombre pues esa grafica genial porque tiene 16GB de vram podras ejecutar el qwen 14B con solvencia |
ForoCoches: Miembro
13-jun-2026 21:06
#5
| Para experimentar, con esa te va a ir bien. Dudo que encuentres algo mejor relación calidad/precio. |
ForoCoches: Miembro
Ayer 00:08
#6
|
Yo soy de la opinión de que si quieres hacer algo realmente util, necesitas 24gb sí o sí. Aunque duela al bolsillo, es la verdad. Hay un salto importante en la capacidad de los modelos de 12-20B que como mucho vas a poder correr a velocidades decentes, y los modelos ya que rondan los 30-35B. Es una compra más práctica una 3090 o una 7900XTX usada que una RTX5000 nueva (excepto la 5090, obviamente) |
ForoCoches: Miembro
Ayer 07:56
#7
|
Yo soy de la opinión de que si quieres hacer algo realmente util, necesitas 24gb sí o sí.
Aunque duela al bolsillo, es la verdad. Hay un salto importante en la capacidad de los modelos de 12-20B que como mucho vas a poder correr a velocidades decentes, y los modelos ya que rondan los 30-35B. Es una compra más práctica una 3090 o una 7900XTX usada que una RTX5000 nueva (excepto la 5090, obviamente) es cierto, pero toda grafica de 24GB estan carisimas en el mercado de segunda mano |
No soy el del avatar
Ayer 09:23
#8
| Ojo que los modelos que puedas ejecutar ahí son muy muy pequeños y no puedes esperar grandes cosas de ellos. |
Mienbro
Ayer 09:49
#9
|
A mi me parece un desembolso increíble para lo poco que se puede conseguir… Vas a ganar mucho en velocidad, pero con 16gb los modelos que se pueden cargar son los que son. Imagino que ya tienes algo montado y sabes lo que esperar, así que si te sobran 600€ pues adelante. Si es por cacharrear, por unos 200€ pillas una bc250+alimentacion, y tienes un engendro con 16gb de RAM que no va a ir tan rápido pero cuesta una tercera parte y podrá cargar los mismos modelos prácticamente. |
ForoCoches: Miembro
Ayer 10:00
#10
|
La 3090 se dejan ver ocasionalmente a 700-800€ Para pruebas del tipo que quiere el OP es lo que mejor veo. |
ForoCoches: Usuario
Ayer 10:21
#11
|
Yo en su día saqué la siguiente cuenta: Si una cuota anual de minimax sale 440€ al año, y tiene una potencia similar a un Claude opus. Con ese dinero no hay gráfica que te haga lo mismo. Dentro de un año, ese montaje que te costó 2000€ pasará a costar 1500€. Tienes para cuatro años del minimax a full. En cuatro años ese pc vale 600€ Salvo para proyectos muy concretos, o como excusa para adquirir un pc gamer, te lo compro. Para el resto, pues tendrás un modelo que correrá meh, sin límites eso sí, manteniendo una privacidad y con una complejidad añadida que en las versiones cloud ya te las evitas. |
ForoCoches: Miembro
Ayer 10:33
#13
| De eso hace casi un año. Verlas a menos de 900 es una rareza hoy en día. |
ForoCoches: Miembro
Ayer 10:38
#14
|
Yo en su día saqué la siguiente cuenta:
Si una cuota anual de minimax sale 440€ al año, y tiene una potencia similar a un Claude opus. Con ese dinero no hay gráfica que te haga lo mismo. Dentro de un año, ese montaje que te costó 2000€ pasará a costar 1500€. Tienes para cuatro años del minimax a full. En cuatro años ese pc vale 600€ Salvo para proyectos muy concretos, o como excusa para adquirir un pc gamer, te lo compro. Para el resto, pues tendrás un modelo que correrá meh, sin límites eso sí, manteniendo una privacidad y con una complejidad añadida que en las versiones cloud ya te las evitas. |
Editado: Ayer 10:42 -
ForoCoches: Miembro
Ayer 11:56
#15
|
yo me tiro de los pelos porque cuando costaban 500 euros de segunda mano las 3090 estuve a punto de pillar una y me eché para atrás, me quedé con mi 3080 10gb ahora que cacharreo bastante con qwen local, me arrepiento tremendamente |
ForoCoches: Miembro
Ayer 12:01
#16
|
Yo en su día saqué la siguiente cuenta:
Si una cuota anual de minimax sale 440€ al año, y tiene una potencia similar a un Claude opus. Con ese dinero no hay gráfica que te haga lo mismo. Dentro de un año, ese montaje que te costó 2000€ pasará a costar 1500€. Tienes para cuatro años del minimax a full. En cuatro años ese pc vale 600€ Salvo para proyectos muy concretos, o como excusa para adquirir un pc gamer, te lo compro. Para el resto, pues tendrás un modelo que correrá meh, sin límites eso sí, manteniendo una privacidad y con una complejidad añadida que en las versiones cloud ya te las evitas. |
ForoCoches: Usuario
Ayer 12:04
#17
|
En LLM lo principal es la cantidad de VRAM y el ancho, la potencia de la GPU es secundario. Con 16GB vas a ir justo para probar cualquier modelo decente como Gemma4 26B o Qwen3.6 27B, lo ideal son 24GB |
ForoCoches: Miembro
Ayer 16:51
#18
|
Hombre, cada vez hay menos, sí. Pero como digo un par de meses buscando cuando se acuerde 3 o 4 veces por semanas y algo ve 100x100. |
ForoCoches: Miembro
Ayer 18:57
#20
| Qué va. Yo tengo un bot que mira las oferta por mi cada 2 horas y me avisa cuando sale algo. Igual aparece 1 al mes en toda mi CCAA y vuela en horas. |
ForoCoches: Miembro
Ayer 19:26
#21
|
Yo estoy moviendo con dos RTX4090 el modelo de Gemma4 (48VRAM) Local 100% ~ |
ForoCoches: Miembro
Ayer 19:58
#22
|
Depende de la privadad que quieras para tus proyectos y el uso que quieras dar (uso intensivo mejor un LLM local). Hay modelos pera desarrollo basante aceptables. -Qwen 3.6 esta muy bien. Pero eso si es cierto, que 16gb de vram se queda corto. |
Editado: Ayer 20:02 -
ForoCoches: Miembro
Ayer 22:03
#23
| Me autocito porque antes lo digo y antes aparece un "chollo" a 842,67€ reacondicionado en amazon. Me avisó mi bot y ya lo pedí. Ahora tengo que buscarle hueco, porque dos tarjetas de estas no son una tontería, va a haber que hacer tetris en la caja. |
Click aquí
Hoy 09:09
#24
Antes de nada, gracias a todos! No me había suscrito al hilo y me extrañaba que no me llegasen respuestas...  En resumen, ya uso suscripciones cloud para lo "serio" (Claude Pro + ChatGPT Plus + DeepSeek por API como fallback). El objetivo no es algo pro, ni picar código para producción ni nada similar. Es mas bien cacharrear, tener privacidad e ir viendo, de cara a tener experiencia con IA local (tengo ahora Ollama, pero va a pedales). Lo que le pediría ahora: - Controlar mi Home Assistant en local - Tareas básicas como clasificar mis movimientos bancarios con ActualBudget (ya lo tengo montado con API y N8N) - Transcripción de audio con WhisperX (quiero reconocimiento de diferentes voces, aunque para cosas serias uso Deepgram) - Formato de texto (envío transcripciones de audio largo a un bot de Telegram. Antes formateo párrafos y esas cosas) - Modelo de fallback para alertas simples de flujos de N8N o similares, que no necesiten razonamiento - Que me sirva para seguir aprendiendo. Con eso, respondo a algunas cosillas interesantes que habéis comentado: Es Hermes. Con GTP 5.4 por debajo, eso sí  Le había dado poca info también. Le había dado poca info también.A priori me sigue interesando la RTX 5060 Ti 16G por 589 € en Amazon. Yo soy de la opinión de que si quieres hacer algo realmente util, necesitas 24gb sí o sí.
Aunque duela al bolsillo, es la verdad. Hay un salto importante en la capacidad de los modelos de 12-20B que como mucho vas a poder correr a velocidades decentes, y los modelos ya que rondan los 30-35B. Es una compra más práctica una 3090 o una 7900XTX usada que una RTX5000 nueva (excepto la 5090, obviamente) A mi me parece un desembolso increíble para lo poco que se puede conseguir…
Vas a ganar mucho en velocidad, pero con 16gb los modelos que se pueden cargar son los que son. Imagino que ya tienes algo montado y sabes lo que esperar, así que si te sobran 600€ pues adelante. Si es por cacharrear, por unos 200€ pillas una bc250+alimentacion, y tienes un engendro con 16gb de RAM que no va a ir tan rápido pero cuesta una tercera parte y podrá cargar los mismos modelos prácticamente. Esta última opción que dices no la conocía, me ha resultado muy interesante, gracias! Crees que puede tirar con lo que qhe añadido al principio de este mensaje? He encontrado este repo y tiene buena info: https://github.com/akandr/bc250 Lo único es que ahora tengo poco tiempo y el proyecto requiere cierto DIY. Tengo que valorarlo bien. Actualizo: parece que con WhisperX, chungo: WhisperX usa CTranslate2 con CUDA. No hay soporte ROCm ni Vulkan para WhisperX (hay un [issue abierto](https://github.com/m-bain/whisperX/issues/566) desde hace meses y sigue sin implementarse). Opciones en BC-250: - ❌ WhisperX — no funciona - ❌ faster-whisper — necesita CUDA - ⚠️ whisper.cpp con backend Vulkan — podría funcionar, pero no probado y rendimiento desconocido Por cierto, me ha aparecido esta, pero no sé si hay algo que esté leyendo mal, porque me parece buen precio (eso si, no cabe en mi servidor Dell, y es algo chungo de cambiar de caja, porque es propietario):  https://www.amazon.es/gp/product/B0B...R4ACA65C&psc=1 |
ForoCoches: Usuario
Hoy 10:20
#25
|
no es mala opción, con 16Gb de VRAM te correrá modelos 7b bastante bien, yo tengo una 3080Ti de 12Gb y esos modelos me los mueve muy bien, y estoy pensando en montarle una Tesla P40, con 24Gb de RAM para sumarle y poder llegar a modelos 30b, a ver si encuentro algo. Edito: La gráfica que mandaste del enlace de amazon no me parece un 3090... por lo menos la foto que tiene en amazon no corresponde con el modelo. Esta es la imagen real: https://m.media-amazon.com/images/I/81GluDP1+RL.jpg además lee los comentarios de la gente en amazon. |
Editado: 10:23 -
ForoCoches: Miembro
Hoy 10:24
#26
|
Antes de nada, gracias a todos! No me había suscrito al hilo y me extrañaba que no me llegasen respuestas...
En resumen, ya uso suscripciones cloud para lo "serio" (Claude Pro + ChatGPT Plus + DeepSeek por API como fallback). El objetivo no es algo pro, ni picar código para producción ni nada similar. Es mas bien cacharrear, tener privacidad e ir viendo, de cara a tener experiencia con IA local (tengo ahora Ollama, pero va a pedales). Lo que le pediría ahora: - Controlar mi Home Assistant en local - Tareas básicas como clasificar mis movimientos bancarios con ActualBudget (ya lo tengo montado con API y N8N) - Transcripción de audio con WhisperX (quiero reconocimiento de diferentes voces, aunque para cosas serias uso Deepgram) - Formato de texto (envío transcripciones de audio largo a un bot de Telegram. Antes formateo párrafos y esas cosas) - Modelo de fallback para alertas simples de flujos de N8N o similares, que no necesiten razonamiento - Que me sirva para seguir aprendiendo. Con eso, respondo a algunas cosillas interesantes que habéis comentado: Es Hermes. Con GTP 5.4 por debajo, eso sí Le había dado poca info también.A priori me sigue interesando la RTX 5060 Ti 16G por 589 € en Amazon. Genial, esa era una de las ideas. Esta última opción que dices no la conocía, me ha resultado muy interesante, gracias! Crees que puede tirar con lo que qhe añadido al principio de este mensaje? He encontrado este repo y tiene buena info: https://github.com/akandr/bc250 Lo único es que ahora tengo poco tiempo y el proyecto requiere cierto DIY. Tengo que valorarlo bien. Actualizo: parece que con WhisperX, chungo: WhisperX usa CTranslate2 con CUDA. No hay soporte ROCm ni Vulkan para WhisperX (hay un [issue abierto](https://github.com/m-bain/whisperX/issues/566) desde hace meses y sigue sin implementarse). Opciones en BC-250: - WhisperX — no funciona - faster-whisper — necesita CUDA - ️ whisper.cpp con backend Vulkan — podría funcionar, pero no probado y rendimiento desconocido Ojalá, no me importaría subir un poco el presupuesto, pero no encuentro ofertas. Por cierto, me ha aparecido esta, pero no sé si hay algo que esté leyendo mal, porque me parece buen precio (eso si, no cabe en mi servidor Dell, y es algo chungo de cambiar de caja, porque es propietario): https://www.amazon.es/gp/product/B0B...R4ACA65C&psc=1 Yo tengo 2x7900XTX, lo que me da 48gb de vram. |
ForoCoches: Miembro
Hoy 10:59
#27
|
eso que has puesto de amazon es un fake como una catedral es imposible que una 3090ti cueste 399 euros y la foto es una 1050 o similar asi que ni caso a ese anuncio |